Ускорение работы PHP
OPCache и JIT. Это нам нужно, если мы пишем что-то сложнее базовых CRUD.
Введение
Как известно, существует два базовых типа языков программирования: это компилируемые и интерпретируемые. Как понятно из их названия, код компилируемых языков перед выполнением должен быть скомпилирован в бинарный код, команды которого будут считываться непосредственно процессором. В отличии от интерпретируемых языков, код которых считывается и транслируется в операционный код (далее -- опкод), который в свою очередь транслируется в бинарный код, который передаётся на исполнение процессору.
Из-за того, что интерпретатор должен сначала прочитать поданный на исполнение файл, интерпретировать его код, загрузить зависимости, транслировать в опкоды, затем опкоды обрабатывает виртуальная машина Zend и только потом передать на исполнение непосредственно процессору, интерпретируемые языки считаются медлительными за счёт этих лишних операций.
Так и было до определённого времени, когда люди поняли, что на production-серверах исходный код приложений меняется достаточно редко и каждый раз считывать и обрабатывать одни и те же файлы -- это лишняя трата времени и можно единожды прочитанный файл держать в памяти в скомпилированном виде, а не перекомпилировать его при каждом запросе.
Так и появилось расширение OPCache.
Цикл жизни скрипта на PHP
Если идти по шагам выполнения скрипта с момента его вызова в PHP, то это выглядит так: Парсинг > Компиляция > Исполнение.
Но если мы добавим расширение OPCache, то в цикл жизни скрипта, между компиляцией и исполнением, добавится ещё два шага: Оптимизация и Кэширование.
Таким образом, с учётом OPCache, цикл жизни скрипта на PHP выглядит так: Парсинг > Компиляция > Оптимизация > Кэширование > Исполнение
Парсинг
Это первый шаг в жизненном цикле скрипта. На данном этапе действую парсер и лексер, которые разбивают код на токены и передают компилятору. Этот процесс называется токенизацией и помогает компилятору понять взаимосвязанность токенов.
Компиляция
На этом шаге происходит превращение полученных токенов в опкоды, в которых уже содержатся инструкции для выполнения приложения.
Оптимизация
Из-за особенностей PHP, отсутствует возможность проведения кросс-файловой оптимизации. Таким образом, оптимизация происходит только на уровне одного файла.
Внутрифайловая оптимизация может оптимизировать заранее известные значения. Например, у нас есть файл с названием script.php и он лежит в директории /tmp. Следующий скрипт будет оптимизирован:
if (__DIR__ == '/tmp') {
echo 'yes';
} else {
echo 'no';
}Так как изначально OPCache знает, где расположен файл, который он собирается оптимизировать, то нет смысла проверять его расположение внутри кода ещё раз и для себя компилятор сократит эту запись до простого
// Если на этапе компиляции файл находился в директории /tmp
echo 'yes';
// В иных случаях
echo 'no';
Вот ещё несколько примеров:
if ($a) {
echo 'foo';
} else {
echo 'bar';
}Здесь компилятор не может заранее предугадать, какое значение будет в переменной $a и оставит проверку во время исполнения
if function_exists('my_custom_function')) { }В данном случае компилятор тоже не сможет оптимизировать код, так как функция my_custom_function не входит в стандартное пространство имён языка. Компилятор не оптимизирует проверку на существование пользовательских функций, так как они могут находиться в других файлах.
if (function_exists('array_merge')) {
echo 'yes';
}Но проверку на существование стандартных функций компилятор оптимизирует, так как её наличие он может проверить в стандартном пространстве имён и результат выполнения данного кода известен заранее.
Так же дела обстоят и с константами. Так как константы никогда не меняются, то компилятор вместо того, чтобы каждый раз вызывать обращение к ним по указателю в памяти, просто подставляет их значение прямо в нужные места в коде.
Таким образом, следующий код
const SOME_STRING = 'foo';
echo SOME_STRING;
Превратится в прямой вывод значения:
echo 'foo';
Кэширование
На этом шаге OPCache выделяет общую память для хранения скриптов. При этом важно понимать, что данный сегмент памяти будет выделен на постоянной основе, то есть не будет ни изменён, ни удалён из памяти.
Размер этого сегмента памяти указывается в настройке opcache.memory_consumption. Разумеется, универсальной рекомендации по настройке размера выделенной памяти не существует, так как у разных приложений разные запросы. Но чем больший объём приложения мы имеем, тем больше памяти для него нужно выделить, что логично. И не забываем, что файлы фреймворков тоже будут скомпилированы и помещены в общую память, таким образом под общий сегмент, лучше выделять столько памяти, сколько не жалко.
Но это если говорить о больших проектах. А если говорить о небольших, то этому блогу, который вы сейчас читаете, достаточно 128MB, из которых занято всего лишь около 50MB.
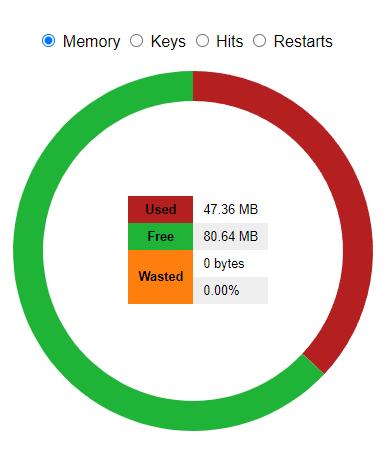
Итак, что же записывает в эту память OPCache? В первую очередь, как несложно догадаться, в общую память записываются неизменяемые данные. Это могут быть , например, скомпилированные классы, а так же функции и константы. Таким образом в памяти хранятся все нужные данные и доступ к ним происходит через указатель, без необходимости повторной компиляции или копирования объектов.
То есть OPCache загружает скрипт, компилирует его, вычисляет точный размер памяти, необходимый для хранения скомпилированных данных и помещает их туда. Таким образом, память никогда не освобождается и не фрагментируется, однажды помещённый объект остаётся доступен в памяти по своему адресу всегда. Возвращаясь к настройке количества выделяемой памяти, не забывайте, что необходимая память -- это не размер файла с кодом, а количество объектов и переменных, которые он создаёт.
JIT компиляция
Стоп! Но ведь выше уже была компиляция, зачем ещё раз про неё говорить?
И да, и нет. JIT компиляция стоит ниже обычный компиляции файлов в опкоды, так как скомпилированные выше опкоды она транслирует уже непосредственно в машинный код, в инструкции процессору, обходя виртуальную машину самого PHP.
Не каждый файл и даже не каждый блок кода будет скомпилирован с помощью JIT. Данный тип компиляции может значительно ускорить логическую часть кода. Это позволит ускорить работу с массивами, манипуляции с байтами, обратку изображений и даже открывает доступ к разработке Machine Learning на PHP! Но компиляция JIT никак не ускорит функции ввода-вывода, так как скорость дисков и сети имеет свои ограничения.
JIT компиляцию, как и любой другой инструмент, нужно применять тогда, когда вы понимаете её необходимость. Она не ускорит среднестатистический блог, так как работа блога -- это по большей части CRUD операции.
Итог
Итак, нужны ли нам OPCache и JIT? Несомненно, нужны! Если приложение не завязано на операции ввода-вывода, а используется, например, для сложных вычислений, то скомпилированный код будет работать значительно быстрее интерпретируемого.
Из личного опыта, могу сказать, что поиск пересекающихся областей после включения JIT заработал значительно быстрее, так как это чисто логическая обработка данных.
Но, разумеется, ни один компилятор не сможет ускорить написанный изначально плохой код. Поэтому на оптимизатор надейся, а сам не плошай!